How to Rank Well in Amazon, the US’s Largest Product Search Engine

Posted by n8ngrimm
The eCommerce SEO community is ignoring a huge opportunity by focusing almost exclusively on Google. But Google is the biggest search engine, right? Actually, if you are in eCommerce, Amazon should be far more important to you than Google, because it has roughly three times more search volume for products.
In 2012, The New York Times reported:
“In 2009, nearly a quarter of shoppers started research for an online purchase on a search engine like Google and 18 percent started on Amazon, according to a Forrester Research study. By last year, almost a third started on Amazon and just 13 percent on a search engine. Product searches on Amazon have grown 73 percent over the last year while searches on Google Shopping have been flat, according to comScore.”
When researching this post, I searched Moz.com for already-published material about ranking in Amazon. All I found was a single Q&A with five responses and little information. Conversely, there are many, many questions on Moz about how to rank your Amazon product pages in Google. It’s all very Google-focused.
I joined DNA Response and the eCommerce vertical from the world of education lead-gen where most of our traffic came from Google. I empathize with the Google myopia from which most SEOs suffer. My goal with this post is twofold:
- First, I want to convince all of the eCommerce search marketers to spend a lot more energy optimizing Amazon.
- Second, I want to provide marketers with a basic understanding of Amazon’s organic ranking algorithm.
Due to the lack of existing content on this topic, I felt the need to be somewhat comprehensive. I will address several conceptual problems I encountered when switching from a Google-focused niche to Amazon then share everything I have learned about Amazon’s ranking algorithms.
(Side note: I would like to apologize in advance that many of the links in my article require an Amazon Seller Central login to view. Amazon requires a login for most of their seller resources.)
Table of contents
- Key Differences Between Amazon and Google
- Results Page Mechanics
- Ranking Factors
- Track your Progress
- Other Visibility Systems
- In Closing

This section is mostly theoretical. Amazon is a fundamentally different search engine than Google so my thinking necessarily evolved when I made the switch from optimizing websites in Google to optimizing products in Amazon.
Conversion vs. user satisfaction
Google built a search engine so they could sell ads. Amazon built a search engine so they can sell products. That creates a basic difference in how each measures success. Google is successful when you find your answer quickly because you will return, perform more searches, and click on ads. Amazon is successful when you to find a great product at a great price and buy it because you will return and buy more products. Google’s search success metrics will revolve around dwell time, click-through-rate, search refinement rate, etc. Amazon can measure success by revenue or gross margin per search. If Amazon can sell more products by rearranging their search results, they will do that.
Because the two search engines measure success differently, the metrics you analyze to predict rankings success change. When optimizing for Google you focus on improving user engagement metrics and building external trust factors, because those factors tell Google that the users it sends to your website will be happy. Happy users equals more money for Google. When optimizing for Amazon, focus on improving conversion rates. More conversions equals more money for Amazon.
Structured vs. unstructured data
While Google has been encouraging site owners to add more structured data to their websites, the data in Amazon’s index is already completely structured. Here’s a screenshot of the page where a seller enters data about a product. Every field has a name, a definition, and sometimes a defined list of valid values:

Now compare that to the basic way to build a web page.
 Site owners have a blank slate where they can express… anything. In Amazon, you need to give Amazon exactly what they want in the format they specify. Because Amazon has already determined the type of information you can give them about your product, spend time providing accurate and complete product data.
Site owners have a blank slate where they can express… anything. In Amazon, you need to give Amazon exactly what they want in the format they specify. Because Amazon has already determined the type of information you can give them about your product, spend time providing accurate and complete product data.
On-page vs. on-page + off-page
With Google you spend a lot of your time optimizing your off-page signals. You build links, manage a social media presence, and encourage brand mentions because Google is measuring those signals to calculate the popularity and trust of your website. While these activities may have secondary effects on a products ranking in Amazon (greater brand awareness creates more branded search leading to a higher sales rank and conversion rate leading Amazon to rank you higher), building a link to your blue widget page on Amazon will not directly improve its ranking for the search term “blue widget.”
On Amazon, that leaves you with optimizing for conversions, which can be frustrating due to the sparse user behavior data. Here’s all the data you get about user behavior on your listings.

Compared to an analytics package like Google Analytics, it’s nothing. You can’t even view a product’s page views or conversion rate over time without downloading one report per day, week, or month and combining it in Excel.
Compelling vs. unique content
When I first started working with online marketplaces I thought, “We need to write a unique description and bullet points for every marketplace we sell on or else Google won’t rank us well.” I didn’t realize that the bulk of our search traffic in Amazon comes from internal site search and Amazon doesn’t care if your listing has the exact same title, bullets, description, and images as another website. They just care if it converts their searchers into purchasers.
(By the way, I’m not saying that compelling and unique content are mutually exclusive.)

To properly interpret what a ranking means, you should understand the anatomy of a search results page. Like Google, Amazon’s search results pages can have several different looks depending on what type of search you entered.
Anatomy of the results page
Amazon has two formats for their results: a list view for searches in all departments and a gallery view when you search within a specific department or category. The list view contains 15 results per page (sometimes there are 16 results on the first page). The gallery results have 24 results per page.
List view

Gallery view

Some other important elements of the results page are the filter fields in the left sidebar. When a user clicks on a filter, they will see a subset of the original search results. This is one reason why it is so important to complete as many fields as possible when you create a product in Amazon. For instance, Amazon will not know that a blue widget is blue if you don’t fill out the color map field, which means it will be excluded when a user filters to only show blue products.

Finally, there are sponsored products. These are pay-per-click results that show up on the bottom of a search results page. In my experience, if I would like my ad to appear for a specific query, I must include all of the words in the query somewhere in my title or bullet points.

Query string parameters
Amazon builds the URL of a search results page with query parameters much like Google. There are many parameters that might be used but I will review the three most useful. To learn more about the parameters Amazon uses, play around with the filter fields available in the left sidebar and watch how the URL of the search page changes.
field-keywords: Your query in the search bar
node: A numeric string identifying a node in Amazon’s taxonomy (category tree). To determine which number corresponds to which category, navigate to the category on Amazon and find the number Amazon uses in the node parameter in the URL. For instance, the node ID for the Electronics category is 172282. The node IDs are also available in Amazon’s Browse Tree Guides (Seller Central login required).
field-brandtextbin: This represents the brand field. This field is very useful if you want to track how well your product ranks among other products from the same brand. It will not return results if it is the only parameter you include in the search URL. To ensure that you see all products from that brand, include the brand name in the field-keywords parameter.
Here’s how it looks when you use each of these three parameters in one search:
http://www.amazon.com/s?field-keywords=blue widgets&node=172282&field-brandtextbin=pioneer
That URL will search for blue widgets in the electronics category where the brand is pioneer.

First, let’s see what Amazon themselves say about how they rank products. This is an excerpt from a help file in Seller Central titled, Using Search and Browse (Seller Central login required).
“Search is the primary way that customers use to locate products on Amazon.com. Customers search by entering keywords, which are matched against the search terms you enter for a product. Well-chosen search terms increase a product’s visibility and sales. The number of views for a product detail page can increase significantly by adding just one additional search term – if it’s a relevant and compelling term.
“Factors such as price, availability, selection, and sales history help determine where your product appears in a customer’s search results. In general, better-selling products tend to be towards the beginning of the results list. As your sales of a product increase, so does your placement.”
Several statements in those paragraphs are very illuminating. First, search is the “primary” way customers find products. I interpret this to mean that most of the time, Amazon users will perform a search before purchasing. If you want your products to be found on Amazon you must think about search. Second, Amazon mentions some of the data they use to rank products. Specifically they mention the search terms, price, availability (meaning inventory levels), selection (not sure what that means), and sales history.
I will expand on each of these factors and include several more where I have observed an effect on rankings. To further clarify the type of effect each factor has on rankings I separated the factors into two categories: performance factors and relevance factors. A performance factor improves rankings by showing Amazon they will make more money by ranking the product, a relevance factor shows Amazon that a product is relevant to the search of a user.
Performance factors
Performance factors are pretty simple. Amazon wants to rank the product that will generate the most profit for them at the top of each search result. Each of these factors will indicate to Amazon that a product will sell well when ranked well.
Conversion rate
This is a pretty obvious factor to mention, albeit a difficult factor to improve with confidence. Amazon does share units and sessions but does not provide enough data to run A/B tests or even control for specific traffic sources. To find conversion data in Seller Central, navigate to Reports >> Business Reports >> Detail Page Sales and Traffic. Make sure the Unit Session Percentage column is visible. This is simply the number of units ordered divided by the number of sessions your listing received.
Amazon’s Definition of a session is: Sessions are visits to your Amazon.com pages by a user. All activity within a 24-hour period is considered a session.
If your offer is competing with other offers for the same product, be sure to weight your units ordered by your buy box percentage. Otherwise, you product will look like it converts more poorly than it actually does. Amazon will show you all of the sessions a listing received regardless of who was in the buy box but they only show you the number of units ordered from your seller account. If you had 50% of the buy box for a time period you probably received half of the total orders for the listing. Therefore the unit session percentage reported should be half of the unit session percentage observed across all sellers.
Images
Amazon strongly encourages sellers to follow their image guidelines. On their image requirements page they encourage sellers to upload images larger than 1000×1000 pixels (the size required to activate their zoom feature) by saying, “Zoom has proven to enhance sales.”
By including images that meet Amazon’s guidelines, you will ensure that your listings are not suppressed (which kills all sales) and possibly increase conversion rates. As Amazon stated on their Search and Browse page, more sales equals better rankings.
Price
Price often strongly influences conversion rates and units sales. If the price on Amazon compares well to the same product offered on other websites and retail stores, comparison shoppers will be more likely to buy from Amazon and vice versa.
Also consider how your product’s price compares to other products in the same category. My company used to sell a battery-operated vacuum pooper scooper that cost $150. It never ranked very well for searches like “pooper scooper.” I believe this was partly because every other pooper scooper costs between $10 and $20. If customers are used to paying $10 for a pooper scooper it takes a lot of convincing for them to shell out $150. Amazon either observed a low conversion rate and did not rank the product or predicted a low conversion rate and did not rank the product. Either way, the price probably kept our $150 pooper scooper from ranking well.
Relevance factors
Amazon will analyze the following fields to determine if a product is relevant to a search.
Title
The title of a product is one of the most important places to include keywords. Amazon suggests incorporating the following attributes in product titles.
- Brand and description
- Product line
- Material or key ingredient
- Color
- Size
- Quantity
What they do not mention, probably because they want to discourage keyword stuffing, is that you should include an important keyword in the product title. A title is also critical for earning a high click-through-rate and conversion rate by clearly stating what the product is. Since sales factor prominently in ranking, keyword-stuffed titles that discourage users from clicking will ultimately harm your rankings.
As an example of an optimized title, we sell a mineral sunscreen called Brush on Block. In addition to the brand/product name we want to make sure to include the keyword “mineral sunscreen” in the title. It helps users understand what the product is and it’s a valuable keyword. Our title is Brush On Block Broad Spectrum SPF 30 Mineral Powder Sunscreen.
Brand
The brand field in Amazon appears here on the product page. It will always link to a search result of more products from the same brand. When you list products, always include the proper brand name. It is very common for consumers to search for products based on their brand name, so be sure to include the correct one. If a product has multiple brand names you could use, use Google’s Keyword Planner to see which brand is searched most frequently.
Bullets and description
Anecdotally, the bullet points seem to be more influential on search rankings than the description. One of our clients has a line of products with a celebrity’s name attached to the product. After doing some keyword research in Google, we found that there were several popular ways to search for the celebrity’s name. There were many books written by the celebrity already ranking for these versions of their name. The day after including the celebrity’s name in the bullet points, our products began to appear on the second and third pages of results.
Search terms
If you are used to keywords for SEO and PPC, it’s easy to use the “search terms” fields on Amazon incorrectly. I’ve even seen articles written by industry experts that provide sub-optimal advice for using these fields. If you have a Seller Central account, the Search and Browse help page is worth reading. I’ll summarize what they say as well as give some examples share a few main points here. First, I’ll spell out the guidelines:
- There are five fields that accept 50 characters each.
- You do not need to repeat any words
- Commas will be ignored
- Quotation marks will unnecessarily limit your keyword
- Including multiple variations of the same word is unnecessary
- Including common misspellings is unnecessary
- Order of the search terms may matter
- Do include synonyms or spelling variations (e.g. include sun screen and sunscreen)
When I first started filling out search terms fields in Amazon, I would have done something like this:
| Search Term 1 | Sunblock |
| Search Term 2 | Sunscreen |
| Search Term 3 | Sun block |
| Search Term 4 | Sun screen |
| Search Term 5 | Mineral Sunscreen |
| Search Term 1 | brush on block mineral powder sunscreen sunblock |
| Search Term 2 | sun screen protection spf 30 suntan lotion tan kid |
| Search Term 3 | baby spray face child family natural skin sport |
| Search Term 4 | cream boat women men infant spf30 travel small |
| Search Term 5 | solar defense uv facial sensitive babies |
No word is repeated, there are no variations of the same word and I’ve used as many characters as possible for maximum exposure.
The search terms fields do influence ranking on Amazon. As an easy-to-prove example, one of our clients identified a common spelling of their brand name with only a single, outdated result. After adding the term to the Search Terms fields in all of their products, all of their products began to appear for that spelling of their brand name within an hour.
Seller name
I have not seen anything published about Amazon using seller names to build their search results, but I have seen a few situations that lead me to believe your seller name is used in Amazon’s organic search algorithm:
Situation 1: We sell a line of cell phone cases. There are over 17 million cell phone cases listed on Amazon. I have no idea where ours rank, but it’s nowhere near the top. However, if I search for “cell phone case” + our seller name, I can see all of our cell phone cases close to the top of the results.
Situation 2: We sell some workout DVDs. These do not rank very well amongst the 242,000 results for “workout,” but when you add part of our seller name (it’s made up of two words), you can see our workout DVDs on the first page of results.
Both situations demonstrate that Amazon is using your seller name as part of the content they index for search results. It may not be a good idea to change your seller name to optimize for your top keyword, but it will be used in search.

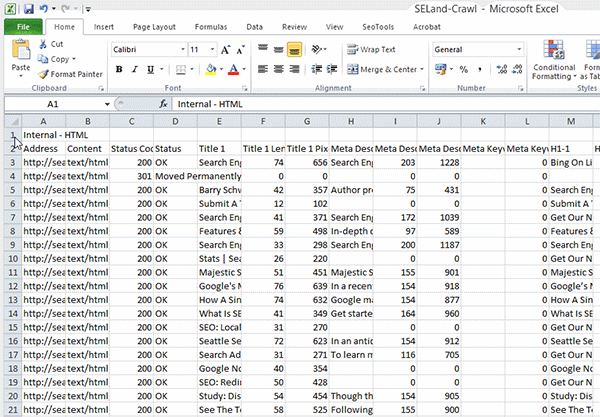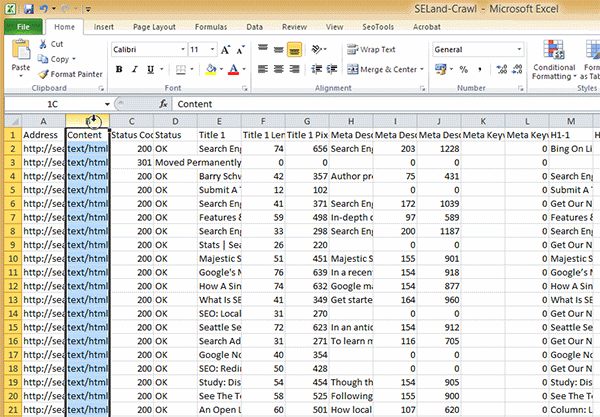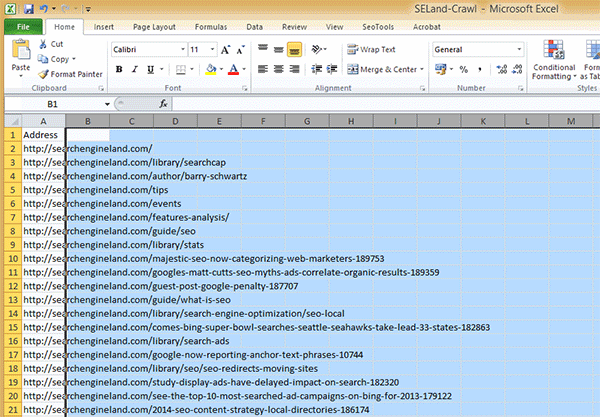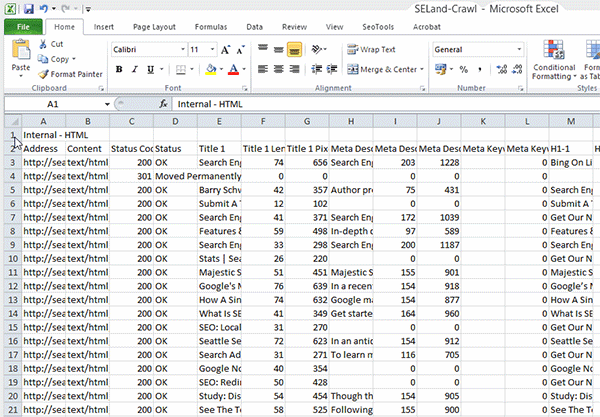
Now that you know what factors Amazon is using to rank products it’s time to get to work. Remember to track your progress to see if your changes help or hurt your rankings. There is a relative lack of testing between ranking factors on Amazon compared to Google, so act with care. To track rankings, I made a simple Google Spreadsheet (which can be improved upon, I’m sure).
UPDATE: The Google Spreadsheet was acting up, so I created this Excel version for you to download.
Here is the process I use to record rankings every day.
Setup
- Make a copy of the spreadsheet so you can edit it.
- Enter the ASINs you would like to track in column E (Don’t edit columns F through H).
- Keep a list of Keywords you want to track in column J.
Daily process
- Copy the first keyword from Column J and paste it into cell B1.
- Wait a few seconds for the spreadsheet to load the top 240 ASINs returned by Amazon.
- When Columns A through C are full of data, you should see your rankings in column G.
- In the example spreadsheet, I would highlight columns E3:H5 and copy
- To store the data, go to the Historical Data tab and paste values at the end of the table.
- To paste values only, right click the first empty cell in column A, mouse over “Paste special,” and click on “Paste values only.”
- If you do a normal paste, it will preserve the formulas and look wrong.
To analyze rankings changes over time, I download the file as an .xlsx, open it with Excel, highlight the table of data on the Historical Data tab and insert a pivot chart.
(Disclaimer: This spreadsheet uses scraped data from Amazon. Amazon may change the structure of their pages at any time, and if it does, this sheet may stop working. If this data is important to your business, make sure you understand the xpath used to scrape Amazon and are ready to fix it if Amazon changes its HTML.)

Here are a few other factors that may help increase your sales or ranking. I do not have any explicit statements, studies, or experience proving a relationship but they are worth trying out. I would encourage you to study the effect of these fields on rankings and sales.
Filter fields
Next to every search result is a list of attributes that allow users to filter their results. For your top keywords, make sure your product has a value filled out for each category of fields to ensure your product is still visible when users filter by color, size, or any other attribute. The Category, Eligible for Free Shipping, Brand, Avg. Customer Review, and Condition fields are visible on most search results.
Reviews
More reviews and better ratings might lead to better sales. Most products that rank well for broad searches have many reviews but it is difficult to tell if the good reviews lead to more sales or if high sales volume leads to more reviews. You can encourage more reviews by emailing your purchasers and asking them to leave a review.
Sales rank
Amazon maintains best sellers lists and reports a listings best sellers ranking for relevant categories on the listing page. This can be a quick way to see how your products’ sales histories compare to similar products.

Parent-child products
What if you could combine the sales histories of several similar products into one? Well, maybe you can. If you sell a product with several size or color options you can list them as a variation and combine them into one listing. While Amazon will combine the reviews from all listings onto the new listing, it’s unclear whether this leads to better rankings by combining the sales histories of the different options.
For instructions on configuring your products as parent/child listings, see the Creating Parent/Child Variation Relationships page in Seller Central (login required).
MPN
We have observed several products with significant search volume for the manufacturer part number (MPN). Check with the manufacturer to make sure you have the correct MPN on your listing.

There are so many topics related to selling on Amazon that I cannot possibly cover them in one blog post. I would like to mention that even with the best organic optimization you can still have poor sales for a product if you don’t understand how to win the Amazon buy box, maintain a good seller rating, or keep inventory in stock. There are a lot of good resources that already exist on these topics.
I hope that, as a community, we can continue to study and educate ourselves on Amazon’s algorithm. It’s a more important search engine than Google in the world of eCommerce, and it continues to gain market share in the US. Ignore it at your own risk.
Did I miss anything? Do you have any questions about your company’s products? Ask away in the comments or get in touch with us at DNA Response.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
Continue reading →