
Posted by Joe.Robison
A lot has changed in the five years since I first wrote about what was Google Webmaster Tools, now named Google Search Console. Google has unleashed significantly more data that promises to be extremely useful for SEOs. Since we’ve long since lost sufficient keyword data in Google Analytics, we’ve come to rely on Search Console more than ever. The “Search Analytics” and “Links to Your Site” sections are two of the top features that did not exist in the old Webmaster Tools.
While we may never be completely satisfied with Google’s tools and may occasionally call their bluffs, they do release some helpful information (from time to time). To their credit, Google has developed more help docs and support resources to aid Search Console users in locating and fixing errors.
Despite the fact that some of this isn’t as fun as creating 10x content or watching which of your keywords have jumped in the rankings, this category of SEO is still extremely important.
Looking at it through Portent’s epic visualization of how Internet marketing pieces fit together, fixing crawl errors in Search Console fits squarely into the “infrastructure” piece:
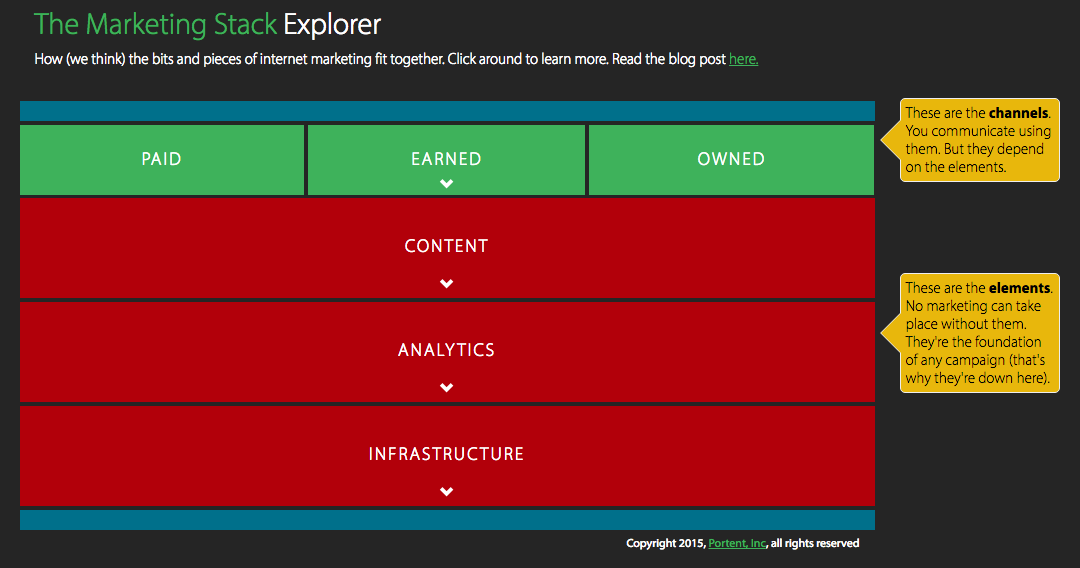
If you can develop good habits and practice preventative maintenance, weekly spot checks on crawl errors will be perfectly adequate to keep them under control. However, if you fully ignore these (pesky) errors, things can quickly go from bad to worse.
Crawl Errors layout
One change that has evolved over the last few years is the layout of the Crawl Errors view within Search Console. Search Console is divided into two main sections: Site Errors and URL Errors.
Categorizing errors in this way is pretty helpful because there’s a distinct difference between errors at the site level and errors at the page level. Site-level issues can be more catastrophic, with the potential to damage your site’s overall usability. URL errors, on the other hand, are specific to individual pages, and are therefore less urgent.
The quickest way to access Crawl Errors is from the dashboard. The main dashboard gives you a quick preview of your site, showing you three of the most important management tools: Crawl Errors, Search Analytics, and Sitemaps.
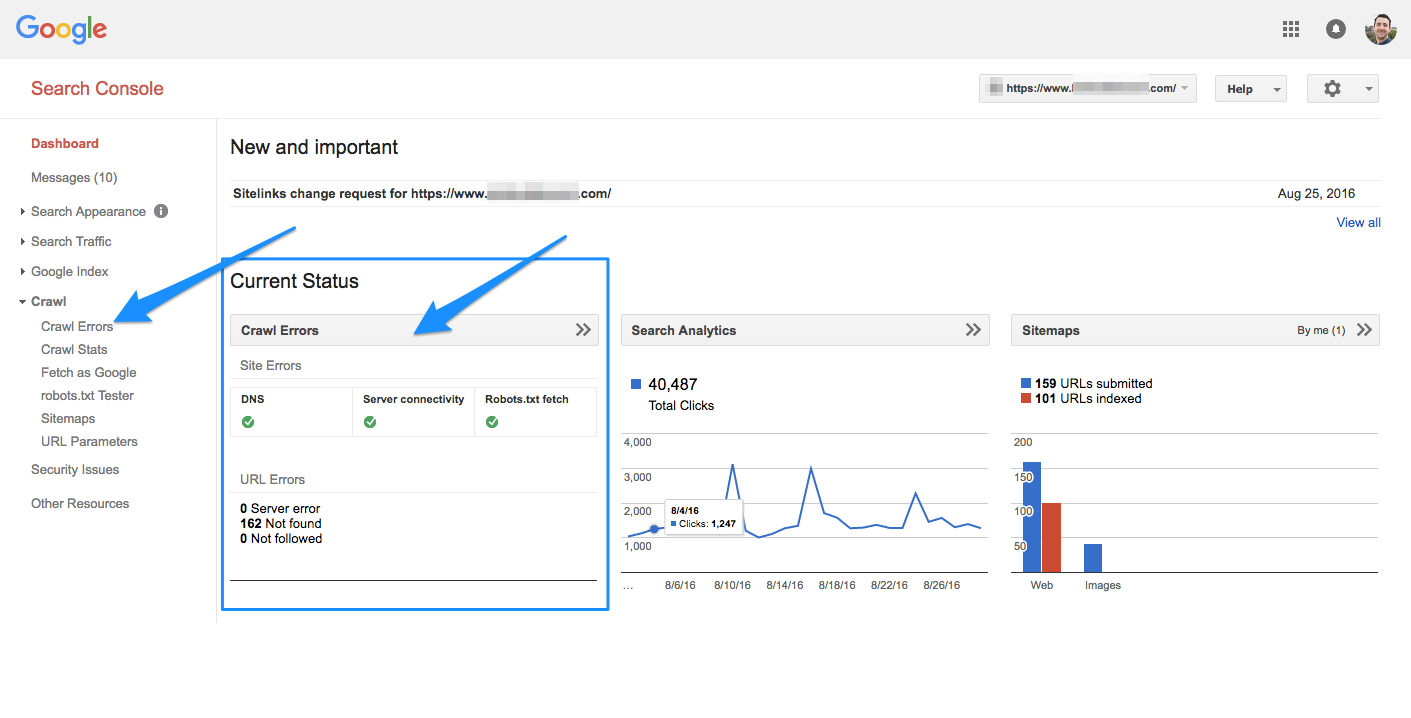
You can get a quick look at your crawl errors from here. Even if you just glance at it daily, you’ll be much further ahead than most site managers.
1. Site Errors
The Site Errors section shows you errors from your website as a whole. These are the high-level errors that affect your site in its entirety, so don’t skip these.
In the Crawl Errors dashboard, Google will show you these errors for the last 90 days.
If you have some type of activity from the last 90 days, your snippet will look like this:
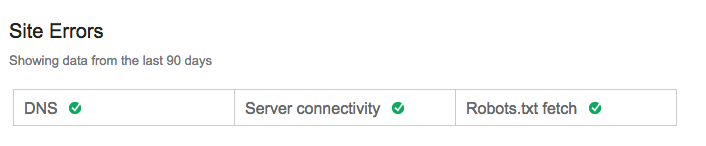
If you’ve been 100% error-free for the last 90 days with nothing to show, it will look like this:
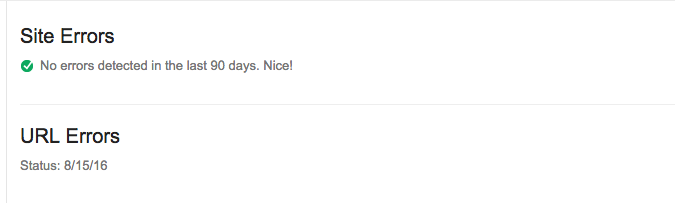
That’s the goal — to get a “Nice!” from Google. As SEOs we don’t often get any validation from Google, so relish this rare moment of love.
How often should you check for site errors?
In an ideal world you would log in daily to make sure there are no problems here. It may get monotonous since most days everything is fine, but wouldn’t you kick yourself if you missed some critical site errors?
At the extreme minimum, you should check at least every 90 days to look for previous errors so you can keep an eye out for them in the future — but frequent, regular checks are best.
We’ll talk about setting up alerts and automating this part later, but just know that this section is critical and you should be 100% error-free in this section every day. There’s no gray area here.
A) DNS Errors
What they mean
DNS errors are important — and the implications for your website if you have severe versions of these errors is huge.
DNS (Domain Name System) errors are the first and most prominent error because if the Googlebot is having DNS issues, it means it can’t connect with your domain via a DNS timeout issue or DNS lookup issue.
Your domain is likely hosted with a common domain company, like Namecheap or GoDaddy, or with your web hosting company. Sometimes your domain is hosted separately from your website hosting company, but other times the same company handles both.
Are they important?
While Google states that many DNS issues still allow Google to connect to your site, if you’re getting a severe DNS issue you should act immediately.
There may be high latency issues that do allow Google to crawl the site, but provide a poor user experience.
A DNS issue is extremely important, as it’s the first step in accessing your website. You should take swift and violent action if you’re running into DNS issues that prevent Google from connecting to your site in the first place.
How to fix
- First and foremost, Google recommends using their Fetch as Google tool to view how Googlebot crawls your page. Fetch as Google lives right in Search Console.
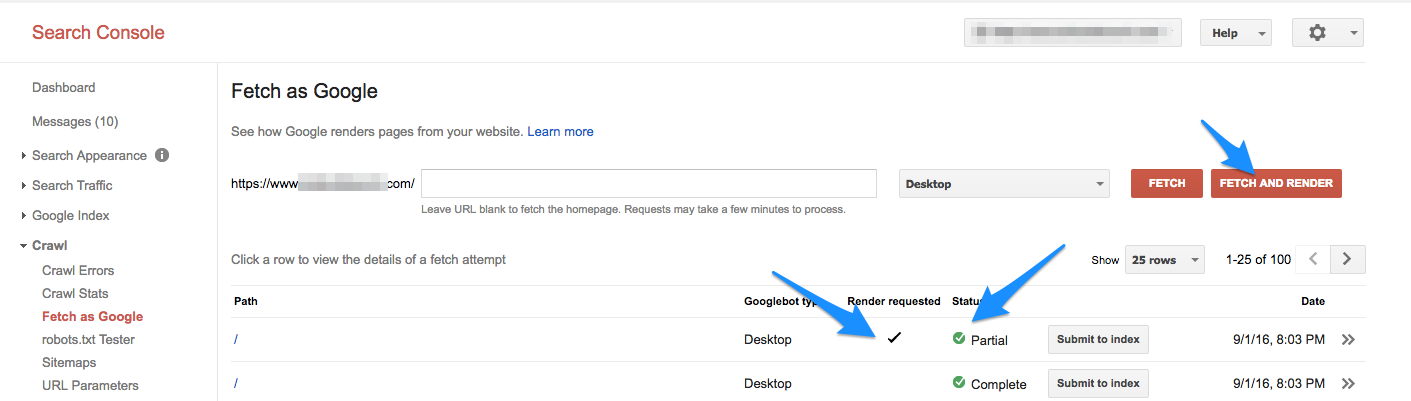
If you’re only looking for the DNS connection status and are trying to act quickly, you can fetch without rendering. The slower process of Fetch and Render is useful, however, to get a side-by-side comparison of how Google sees your site compared to a user.
- Check with your DNS provider. If Google can’t fetch and render your page properly, you’ll want to take further action. Check with your DNS provider to see where the issue is. There could be issues on the DNS provider’s end, or it could be worse.
- Ensure your server displays a 404 or 500 error code. Instead of having a failed connection, your server should display a 404 (not found) code or a 500 (server error) code. These codes are more accurate than having a DNS error.
Other tools
- ISUP.me – Lets you know instantly if your site is down for everyone, or just on your end.
- Web-Sniffer.net – shows you the current HTTP(s) request and response header. Useful for point #3 above.
B) Server Errors
What they mean
A server error most often means that your server is taking too long to respond, and the request times out. The Googlebot that’s trying to crawl your site can only wait a certain amount of time to load your website before it gives up. If it takes too long, the Googlebot will stop trying.
Server errors are different than DNS errors. A DNS error means the Googlebot can’t even lookup your URL because of DNS issues, while server errors mean that although the Googlebot can connect to your site, it can’t load the page because of server errors.
Server errors may happen if your website gets overloaded with too much traffic for the server to handle. To avoid this, make sure your hosting provider can scale up to accommodate sudden bursts of website traffic. Everybody wants their website to go viral, but not everybody is ready!
Are they important?
Like DNS errors, a server error is extremely urgent. It’s a fundamental error, and harms your site overall. You should take immediate action if you see server errors in Search Console for your site.
Making sure the Googlebot can connect to the DNS is an important first step, but you won’t get much further if your website doesn’t actually show up. If you’re running into server errors, the Googlebot won’t be able to find anything to crawl and it will give up after a certain amount of time.
How to fix
In the event that your website is running fine at the time you encounter this error, that may mean there were server errors in the past Though this error may have been resolved for now, you should still make some changes to prevent it from happening again.
This is Google’s official direction for fixing server errors:
“Use Fetch as Google to check if Googlebot can currently crawl your site. If Fetch as Google returns the content of your homepage without problems, you can assume that Google is generally able to access your site properly.”
Before you can fix your server errors issue, you need to diagnose specifically which type of server error you’re getting, since there are many types:
- Timeout
- Truncated headers
- Connection reset
- Truncated response
- Connection refused
- Connect failed
- Connect timeout
- No response
Addressing how to fix each of these is beyond the scope of this article, but you should reference Google Search Console help to diagnose specific errors.
C) Robots failure
A Robots failure means that the Googlebot cannot retrieve your robots.txt file, located at [yourdomain.com]/robots.txt.
What they mean
One of the most surprising things about a robots.txt file is that it’s only necessary if you don’t want Google to crawl certain pages.
From Search Console help, Google states:
“You need a robots.txt file only if your site includes content that you don’t want search engines to index. If you want search engines to index everything in your site, you don’t need a robots.txt file — not even an empty one. If you don’t have a robots.txt file, your server will return a 404 when Googlebot requests it, and we will continue to crawl your site. No problem.”
Are they important?
This is a fairly important issue. For smaller, more static websites without many recent changes or new pages, it’s not particularly urgent. But the issue should still be fixed.
If your site is publishing or changing new content daily, however, this is an urgent issue. If the Googlebot cannot load your robots.txt, it’s not crawling your website, and it’s not indexing your new pages and changes.
How to fix
Ensure that your robots.txt file is properly configured. Double-check which pages you’re instructing the Googlebot to not crawl, as all others will be crawled by default. Triple-check the all-powerful line of “Disallow: /” and ensure that line DOES NOT exist unless for some reason you do not want your website to appear in Google search results.
If your file seems to be in order and you’re still receiving errors, use a server header checker tool to see if your file is returning a 200 or 404 error.
What’s interesting about this issue is that it’s better to have no robots.txt at all than to have one that’s improperly configured. If you have none at all, Google will crawl your site as usual. If you have one returning errors, Google will stop crawling until you fix this file.
For being only a few lines of text, the robots.txt file can have catastrophic consequences for your website. Make sure you’re checking it early and often.
2. URL Errors
URL errors are different from site errors because they only affect specific pages on your site, not your website as a whole.
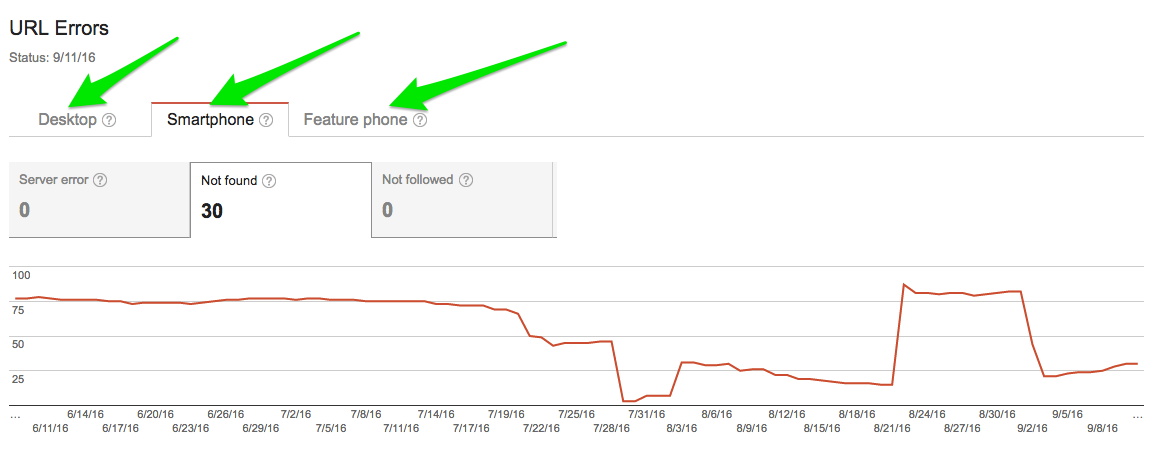
Google Search Console will show you the top URL errors per category — desktop, smartphone, and feature phone. For large sites, this may not be enough data to show all the errors, but for the majority of sites this will capture all known problems.
Tip: Going crazy with the amount of errors? Mark all as fixed.
Many site owners have run into the issue of seeing a large number of URL errors and getting freaked out. The important thing to remember is a) Google ranks the most important errors first and b) some of these errors may already be resolved.
If you’ve made some drastic changes to your site to fix errors, or believe a lot of the URL errors are no longer happening, one tactic to employ is marking all errors as fixed and checking back up on them in a few days.
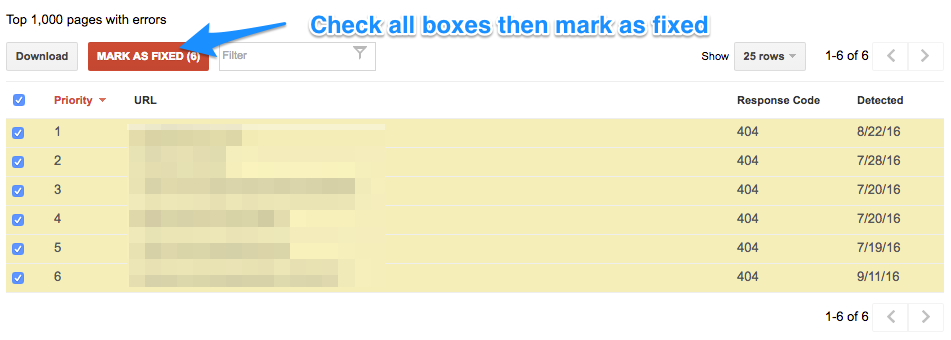
When you do this, your errors will be cleared out of the dashboard for now, but Google will bring the errors back the next time it crawls your site over the next few days. If you had truly fixed these errors in the past, they won’t show up again. If the errors still exist, you’ll know that these are still affecting your site.
A) Soft 404
A soft 404 error is when a page displays as 200 (found) when it should display as 404 (not found).
What they mean
Just because your 404 page looks like a 404 page doesn’t mean it actually is one. The user-visible aspect of a 404 page is the content of the page. The visible message should let users know the page they requested is gone. Often, site owners will have a helpful list of related links the users should visit or a funny 404 response.

The flipside of a 404 page is the crawler-visible response. The header HTTP response code should be 404 (not found) or 410 (gone).
A quick refresher on how HTTP requests and responses look:
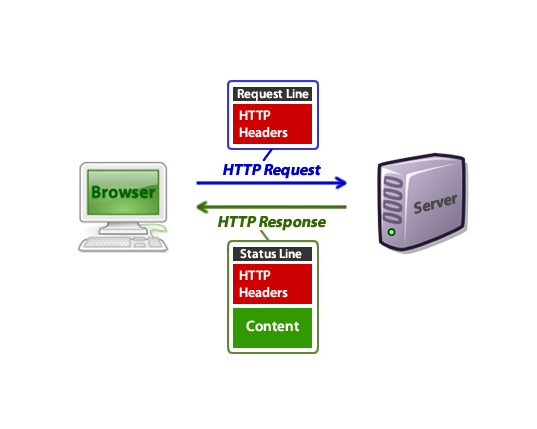
Image source: Tuts Plus
If you’re returning a 404 page and it’s listed as a Soft 404, it means that the header HTTP response code does not return the 404 (not found) response code. Google recommends “that you always return a 404 (not found) or a 410 (gone) response code in response to a request for a non-existing page.”

Another situation in which soft 404 errors may show up is if you have pages that are 301 redirecting to non-related pages, such as the home page. Google doesn’t seem to explicitly state where the line is drawn on this, only making mention of it in vague terms.
Officially, Google says this about soft 404s:
“Returning a code other than 404 or 410 for a non-existent page (or redirecting users to another page, such as the homepage, instead of returning a 404) can be problematic.”
Although this gives us some direction, it’s unclear when it’s appropriate to redirect an expired page to the home page and when it’s not.
In practice, from my own experience, if you’re redirecting large amounts of pages to the home page, Google can interpret those redirected URLs as soft 404s rather than true 301 redirects.
Conversely, if you were to redirect an old page to a closely related page instead, it’s unlikely that you’d trigger the soft 404 warning in the same way.
Are they important?
If the pages listed as soft 404 errors aren’t critical pages and you’re not eating up your crawl budget by having some soft 404 errors, these aren’t an urgent item to fix.
If you have crucial pages on your site listed as soft 404s, you’ll want to take action to fix those. Important product, category, or lead gen pages shouldn’t be listed as soft 404s if they’re live pages. Pay special attention to pages critical to your site’s moneymaking ability.
If you have a large amount of soft 404 errors relative to the total number of pages on your site, you should take swift action. You can be eating up your (precious?) Googlebot crawl budget by allowing these soft 404 errors to exist.
How to fix
For pages that no longer exist:
- Allow to 404 or 410 if the page is gone and receives no significant traffic or links. Ensure that the server header response is 404 or 410, not 200.
- 301 redirect each old page to a relevant, related page on your site.
- Do not redirect broad amounts of dead pages to your home page. They should 404 or be redirected to appropriate similar pages.
For pages that are live pages, and are not supposed to be a soft 404:
- Ensure there is an appropriate amount of content on the page, as thin content may trigger a soft 404 error.
- Ensure the content on your page doesn’t appear to represent a 404 page while serving a 200 response code.
Soft 404s are strange errors. They lead to a lot of confusion because they tend to be a strange hybrid of 404 and normal pages, and what is causing them isn’t always clear. Ensure the most critical pages on your site aren’t throwing soft 404 errors, and you’re off to a good start!
B) 404
A 404 error means that the Googlebot tried to crawl a page that doesn’t exist on your site. Googlebot finds 404 pages when other sites or pages link to that non-existent page.
What they mean
404 errors are probably the most misunderstood crawl error. Whether it’s an intermediate SEO or the company CEO, the most common reaction is fear and loathing of 404 errors.
Google clearly states in their guidelines:
“Generally, 404 errors don’t affect your site’s ranking in Google, so you can safely ignore them.”
I’ll be the first to admit that “you can safely ignore them” is a pretty misleading statement for beginners. No — you cannot ignore them if they are 404 errors for crucial pages on your site.
(Google does practice what it preaches, in this regard — going to google.com/searchconsole returns a 404 instead of a helpful redirect to google.com/webmasters)
Distinguishing between times when you can ignore an error and when you’ll need to stay late at the office to fix something comes from deep review and experience, but Rand offered some timeless advice on 404s back in 2009:
“When faced with 404s, my thinking is that unless the page:
A) Receives important links to it from external sources (Google Webmaster Tools is great for this),
B) Is receiving a substantive quantity of visitor traffic,
and/or
C) Has an obvious URL that visitors/links intended to reach
It’s OK to let it 404.”
The hard work comes in deciding what qualifies as important external links and substantive quantity of traffic for your particular URL on your particular site.
Annie Cushing also prefers Rand’s method, and recommends:
“Two of the most important metrics to look at are backlinks to make sure you don’t lose the most valuable links and total landing page visits in your analytics software. You may have others, like looking at social metrics. Whatever you decide those metrics to be, you want to export them all from your tools du jour and wed them in Excel.”
One other thing to consider not mentioned above is offline marketing campaigns, podcasts, and other media that use memorable tracking URLs. It could be that your new magazine ad doesn’t come out until next month, and the marketing department forgot to tell you about an unimportant-looking URL (example.com/offer-20) that’s about to be plastered in tens thousands of magazines. Another reason for cross-department synergy.
Are they important?
This is probably one of the trickiest and simplest problems of all errors. The vast quantity of 404s that many medium to large sites accumulate is enough to deter action.
404 errors are very urgent if important pages on your site are showing up as 404s. Conversely, like Google says, if a page is long gone and doesn’t meet our quality criteria above, let it be.
As painful as it might be to see hundreds of errors in your Search Console, you just have to ignore them. Unless you get to the root of the problem, they’ll continue showing up.
How to fix 404 errors
If your important page is showing up as a 404 and you don’t want it to be, take these steps:
- Ensure the page is published from your content management system and not in draft mode or deleted.
- Ensure the 404 error URL is the correct page and not another variation.
- Check whether this error shows up on the www vs non-www version of your site and the http vs https version of your site. See Moz canonicalization for more details.
- If you don’t want to revive the page, but want to redirect it to another page, make sure you 301 redirect it to the most appropriate related page.
In short, if your page is dead, make the page live again. If you don’t want that page live, 301 redirect it to the correct page.
How to stop old 404s from showing up in your crawl errors report
If your 404 error URL is meant to be long gone, let it die. Just ignore it, as Google recommends. But to prevent it from showing up in your crawl errors report, you’ll need to do a few more things.
As yet another indication of the power of links, Google will only show the 404 errors in the first place if your site or an external website is linking to the 404 page.
In other words, if I type in your-website-name.com/unicorn-boogers, it won’t show up in your crawl errors dashboard unless I also link to it from my website.
To find the links to your 404 page, go to your Crawl Errors > URL Errors section:
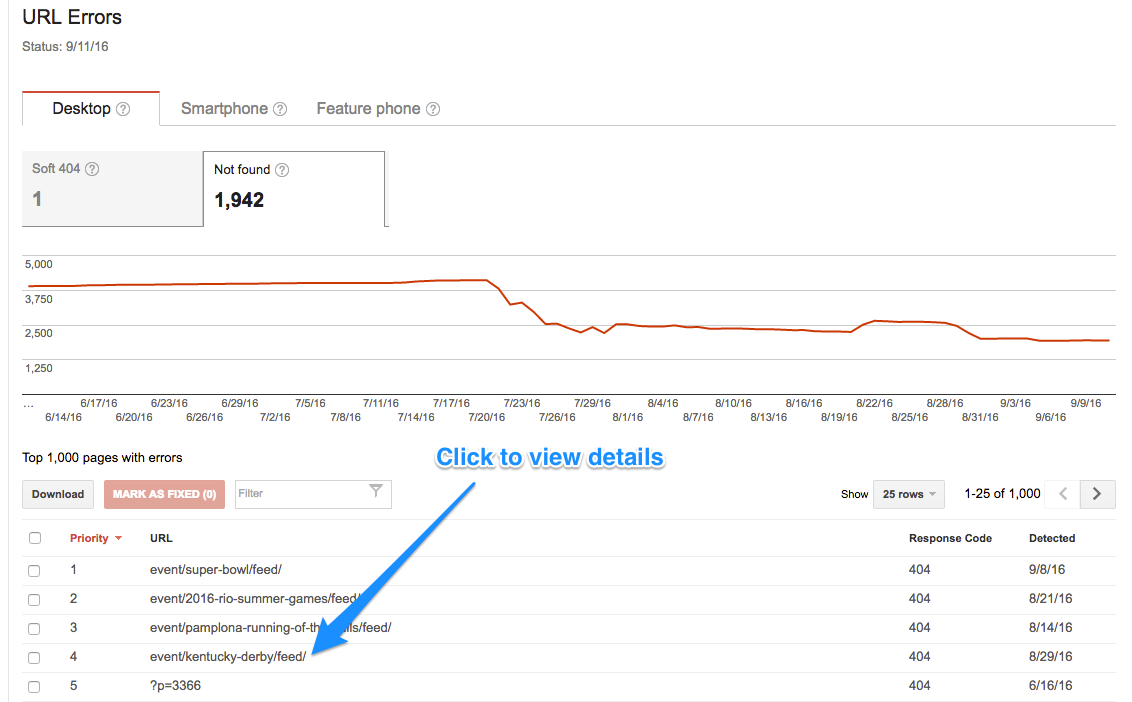
Then click on the URL you want to fix:
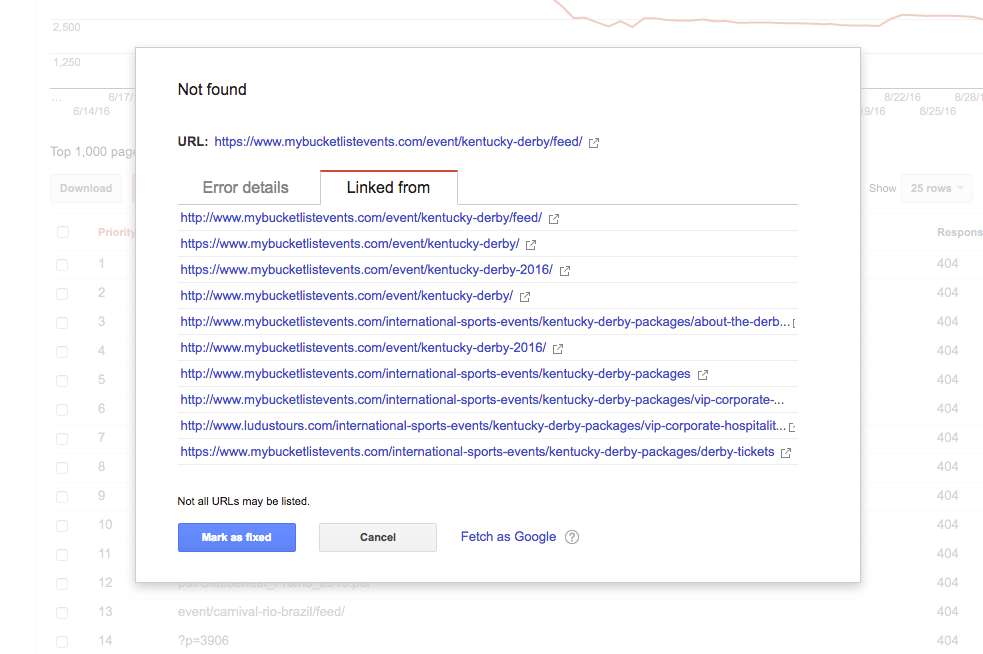
Search your page for the link. It’s often faster to view the source code of your page and find the link in question there:
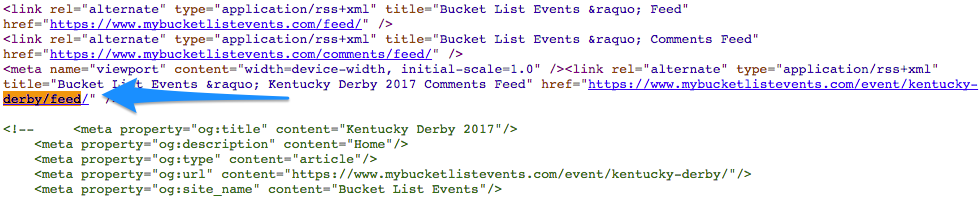
It’s painstaking work, but if you really want to stop old 404s from showing up in your dashboard, you’ll have to remove the links to that page from every page linking to it. Even other websites.
What’s really fun (not) is if you’re getting links pointed to your URL from old sitemaps. You’ll have to let those old sitemaps 404 in order to totally remove them. Don’t redirect them to your live sitemap.
C) Access denied
Access denied means Googlebot can’t crawl the page. Unlike a 404, Googlebot is prevented from crawling the page in the first place.
What they mean
Access denied errors commonly block the Googlebot through these methods:
- You require users to log in to see a URL on your site, therefore the Googlebot is blocked
- Your robots.txt file blocks the Googlebot from individual URLs, whole folders, or your entire site
- Your hosting provider is blocking the Googlebot from your site, or the server requires users to authenticate by proxy
Are they important?
Similar to soft 404s and 404 errors, if the pages being blocked are important for Google to crawl and index, you should take immediate action.
If you don’t want this page to be crawled and indexed, you can safely ignore the access denied errors.
How to fix
To fix access denied errors, you’ll need to remove the element that’s blocking the Googlebot’s access:
- Remove the login from pages that you want Google to crawl, whether it’s an in-page or popup login prompt
- Check your robots.txt file to ensure the pages listed on there are meant to be blocked from crawling and indexing
- Use the robots.txt tester to see warnings on your robots.txt file and to test individual URLs against your file
- Use a user-agent switcher plugin for your browser, or the Fetch as Google tool to see how your site appears to Googlebot
- Scan your website with Screaming Frog, which will prompt you to log in to pages if the page requires it
While not as common as 404 errors, access denied issues can still harm your site’s ranking ability if the wrong pages are blocked. Be sure to keep an eye on these errors and rapidly fix any urgent issues.
D) Not followed
What they mean
Not to be confused with a “nofollow” link directive, a “not followed” error means that Google couldn’t follow that particular URL.
Most often these errors come about from Google running into issues with Flash, Javascript, or redirects.
Are they important?
If you’re dealing with not followed issues on a high-priority URL, then yes, these are important.
If your issues are stemming from old URLs that are no longer active, or from parameters that aren’t indexed and just an extra feature, the priority level on these is lower — but you should still analyze them.
How to fix
Google identifies the following as features that the Googlebot and other search engines may have trouble crawling:
- JavaScript
- Cookies
- Session IDs
- Frames
- DHTML
- Flash
Use either the Lynx text browser or the Fetch as Google tool, using Fetch and Render, to view the site as Google would. You can also use a Chrome add-on such as User-Agent Switcher to mimic Googlebot as you browse pages.
If, as the Googlebot, you’re not seeing the pages load or not seeing important content on the page because of some of the above technologies, then you’ve found your issue. Without visible content and links to crawl on the page, some URLs can’t be followed. Be sure to dig in further and diagnose the issue to fix.
For parameter crawling issues, be sure to review how Google is currently handling your parameters. Specify changes in the URL Parameters tool if you want Google to treat your parameters differently.
For not followed issues related to redirects, be sure to fix any of the following that apply:
- Check for redirect chains. If there are too many “hops,” Google will stop following the redirect chain
- When possible, update your site architecture to allow every page on your site to be reached from static links, rather than relying on redirects implemented in the past
- Don’t include redirected URLs in your sitemap, include the destination URL
Google used to include more detail on the Not Followed section, but as Vanessa Fox detailed in this post, a lot of extra data may be available in the Search Console API.
Other tools
E) Server errors & DNS errors
Under URL errors, Google again lists server errors and DNS errors, the same sections in the Site Errors report. Google’s direction is to handle these in the same way you would handle the site errors level of the server and DNS errors, so refer to those two sections above.
They would differ in the URL errors section if the errors were only affecting individual URLs and not the site as a whole. If you have isolated configurations for individual URLs, such as minisites or a different configuration for certain URLs on your domain, they could show up here.
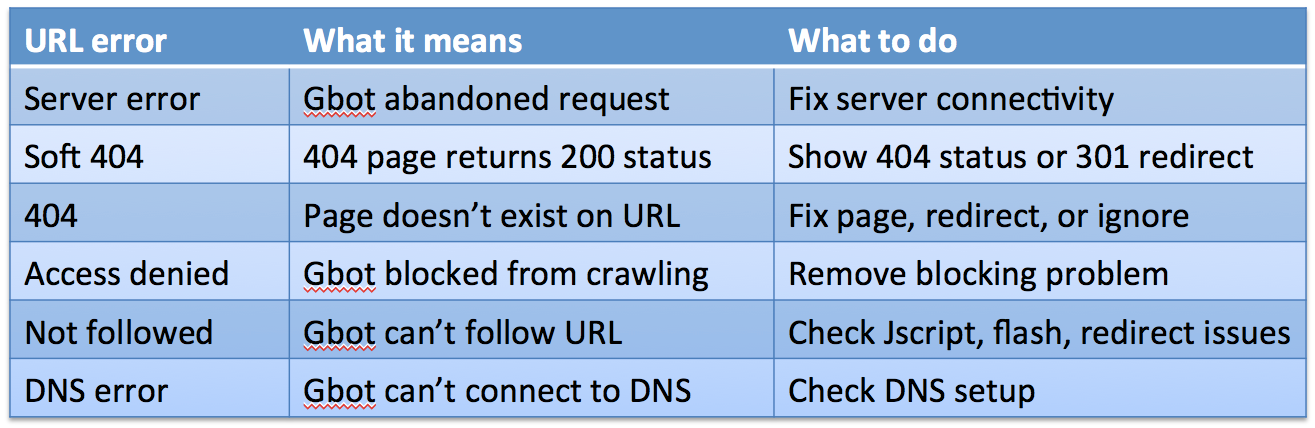
Now that you’re the expert on these URL errors, I’ve created this handy URL error table that you can print out and tape to your desktop or bathroom mirror.
Conclusion
I get it — some of this technical SEO stuff can bore you to tears. Nobody wants to individually inspect seemingly unimportant URL errors, or conversely, have a panic attack seeing thousands of errors on your site.
With experience and repetition, however, you will gain the mental muscle memory of knowing how to react to the errors: which are important and which can be safely ignored. It’ll be second nature pretty soon.
If you haven’t already, I encourage you to read up on Google’s official documentation for Search Console, and keep these URLs handy for future questions:
We’re simply covering the Crawl Errors section of Search Console. Search Console is a data beast on its own, so for further reading on how to make best use of this tool in its entirety, check out these other guides:
Google has generously given us one of the most powerful (and free!) tools for diagnosing website errors. Not only will fixing these errors help you improve your rankings in Google, they help provide a better user experience to your visitors, and help meet your business goals faster.
Your turn: What crawl errors issues and wins have you experienced using Google Search Console?
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
Continue reading →









